Ideology Detection
Data Science Capstone Project for General Assembly | [Complete jupyter notebook at the end of the page]

Abstract
Most of the person has a political bias. Often their sentences too. What if we don’t know the political bias of the person writing or talking? For my capstone project at General Assembly, I proposed a based multi-view model to evaluate sentences with political meaning.
Introduction
Everyone has always referred to this project as a political project. But for me, it’s mainly a philosophical project. In fact, it is a problem on the true meaning of a writing and on the intrinsic meaning of Truth. Truth has always been an important topic in human history, in any aspect of knowledge. From Math to Literature, from physics to Art. In language and in political language, probably even more.
Already 2400 years ago, in Athens, rhetoric started to be an important aspect of political life in the Polis. Socrates, one of the most important philosopher from ancient Greek, had a very harsh debate with the sophists. He described them as Prostitutes of the language. He, in fact, accused them to manipulate people thanks to their debating and dialectic skills. In politics, language is crucial.
Propaganda has been the capstone of totalitarian regimes, but it has been fundamental also in democracy during the cold war. We saw how Political communications changed. Before politicians used to make speeches in the streets. Then a shorter speech or debate on TV. Nowadays they talk with tweets or posts in social media. Shorter and shorter.
Recently everyone saw what probably will be the future of political campaign with the Cambridge Analytica scandal. They used AI to create a bespoke campaign based on a psychological profile created from social media data.
Description
The aim of the project is to detect the ideology of a sentence, using quotes from people with a well known political bias. Trying to capture keys-term that could describe an idea, I want to create a machine to detect the ideology hidden behind social media posts (Twitter, Facebook or Instagram).
The Data | ideologies
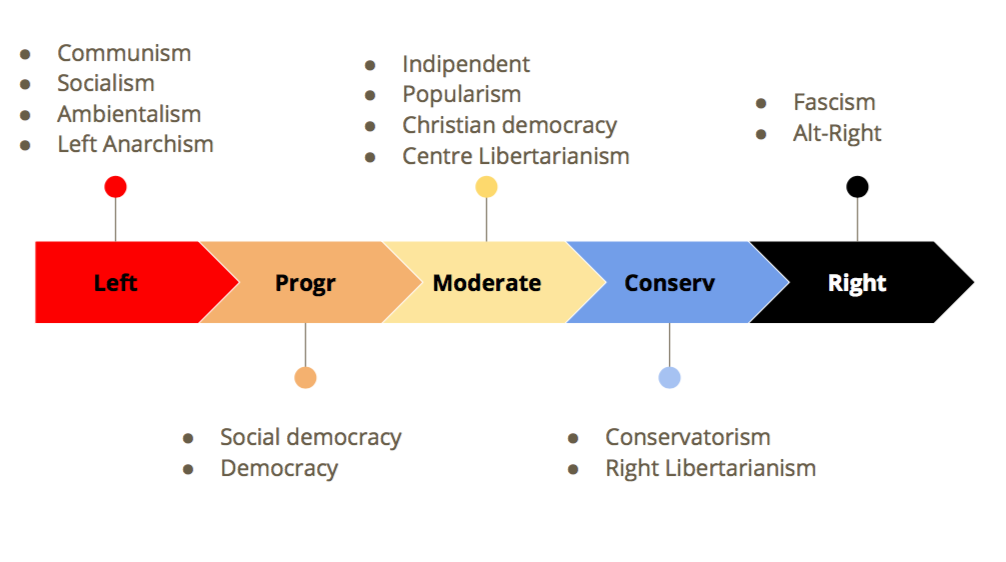
According to Wikipedia, we have almost 20 different macro-ideology. The most common way to visualise the political spectrum is a 2-D dimension graph. The Left-Right spectrum on the x-axis, and the Freedom-Authority on the y-axis. For this project we choose to identify only the Left-Right (x-axis). So the bias of every person will be projected on the x-axis, in only 1-D.

The Data | Biased People and Criteria
Since there is no such Database, I created my own one. The main problem to create a Database with quotes and ideology is my personal Bias. So I chose some Criteria to keep the objectivity:
- Not politician, or not mainly a politician: Since our project is to detect an ideology, politician sometimes diverts from ideology. Popular consent, specific topic and a particular moment of the political scene could push the politician to take different positions.
- English language native, or english main language spoken.
- Personal selection: The first selection comes from my research.
- Objective confirmation - Wikipedia: Every name found in my research has been confirmed by Wikipedia. Wikipedia labeled the political Bias of many public figures. Most of the time it is possible to find it in the “summary-introduction”, sometimes in the paragraph “Political views”.
- Objective confirmation - allsides.com: An alternative way to labeled people is the website allsides.com. This website labeled the political bias of American media and journalist.
- Rejection without confirmation: Without the objective confirmation from one of those websites, the person is rejected and he will not be part of the database.
- The quotes are from 1960 - present.
The Data | Source
I took the quotes from 3 main sources: Goodreads, Wikiquote and Brainquote.
- Goodreads: I used a webapp built using the API of the website and Beautiful Soup
- Wikiquote: There is a python library: wikiquotes
- Brainquote: Scraping with Beautiful Soup
The Data | Ideologies and Authors
0 | Left (Comunism, Socialism, left Anarchism, new Ambientalism, left Populism)
Noam Chomsky, Yanis Varoufakis, Jeremy Rifkin, Naomi Klein, John Bellamy Foster, Raj Patel, Michael Parenti, Michael Hardt and Antonio Negri, George Monbiot, John Gray, Michel Chossudovsky, Perry Anderson, Alexander Cockburn, Terry Eagleton, David Harvey, Fredric Jameson, Raymond Williams, E. P. Thompson, Eric Hobsbawm, Tariq Ali, Angela Davis, Mumia Abu-Jamal, Howard Zinn, Judith Butler, John Holloway, Michael Moore, Michael Kazin, Richard D. Wolff, Steve Ellner, Branko Milanovic, Anthony Barnett, Micheal Otsuka, Jodi Dean, Abby Martin.
1 | Progressive (Social democratic, democratic)
Juan Williams, Bill Moyers, Paul Krugman, Joseph E. Stiglitz, Jesse Jackson, George Soros, Donna Brazile, James Carville, Tony Judt, Jane Jacobs, Lawrence Lessig, Glenn Greenwald, Al Gore, Alan Bennett, Anthony Giddens, Benjamin Barber, Robert Reich, Simon McKay, Ezra Klein, Nicholas Kristof, Sam Harris, Polly Toynbee.
2 | Moderate (Indipendent, Popularism, Christian democracy)
Robert Kagan, Leon Kass, Jonathan Haidt, Ian Bremmer, Thomas Friedman, Peter Drucker, David Brooks, John Avlon, Mark Satin, Arianna Huffington, Ben Bernanke, Joseph Nye, Stephen Walt, Fareed Zakaria, Tibor R Machan, Chris Matthews, David Rockefeller, Peter Thiel, Josh Marshall, Jeffrey D. Sachs, John Rawls, Edward Snowden, Erik Wemple, Maureen Dowd, Lawrence H Summers.
3 | Conservative(Conservative, Conservative Populism)
William F. Buckley Jr.,George Will, Bill O’Reilly, Barry Goldwater,Andrew Sullivan, Robert P George, Roger Stone,Paul Manafort, Milton Friedman,Thomas Sowell,Charles Murray, Kevin D Williamson,Walter E Williams, Robert Lucas Jr,Andrew Breitbart, Bill Kristol,David Friedman, William Happer, Ben Stein, Glenn Beck,Mona Charen,David Frum, David Horowitz, Jeane Kirkpatrick,Charles Krauthammer, Irving Kristol, W. Cleon Skousen,Rush Limbaugh,Tucker Carlson,Andrew Napolitano,Roger Kimball,Michelle Mallon,David Clarke.
4 | Right(Fascism, Alt-Right, right Populism)
David Goodhart, Ben Shapiro, Jared Taylor, David Duke, Matthew Goodwin, Eric Kaufmann, Richard Bertrand, Augustus Sol Invictus, Peter Hitchens, David Irving, Jason Kessler, Sebastian Gorka, Tomislav Sunić, Paul Weyrich, Pat Buchanan, Steve Bannon, Ann Coulter, Milo Yiannopoulos, Vox Day, Steve Sailer, Stefan Molyneux, Alex Jones, John Derbyshire, Mike Cernovich, Peter Brimelow, Katie Hopkins, Laura Loomer, Paul Joseph, Arthur Kemp, Tommy Robinson, Raheem Kassam, Jerome Corsi, Daniel Drezner, Lou Dobbs, Pamela Geller, Robert Spencer, Karl Hess, Hans-Hermann Hoppe, William Luther Pierce, Joel Pollak, Matt Drudge, Nicholas Wade, John R. Bolton, Dinesh D’Souza, Charlie Kirk.
NB: Many of the people from the lists are not in the Database. The names come from my research following the criteria. I made the list before I took the data and it supposed to provide also for Twitter Database, which I couldn’t persuade until the end, for this project. It will be probably part of future implementations.
The Data | Dictionary
- Author
- Quote
- Political Orientation / Target
The Data | Train - Validation - Test
The evaluation has 2 steps. The first one comes from a standard random train/test split. The second one is a made from a small Dataset create which roughly 100 quotes from each category. These 100 quotes come from 4 authors that have not been used for training.
Walkthrough
Problem and consideration about the Data
- Not all the quotes are inherent, but most of it. So I am expecting a lot of “noise”.
- The dataset is very limited. I am going to work with just a bit more than 1500 quotes for each category.
- I am considering the last 60 years for the quotes. Many quotes are of course related to the politics of the period, and for each category, we can see a sort of bias for the time period.
- The categories are balanced in the number of quotes but not in the length, and each category has an imbalance in the quotes by Authors, with the risk that the model will overfit with few of them.
- Since I have a different number of quotes for each category., to create balanced classes I will select randomly the same amount for data for each one. The results could slightly change everytime we select a new bunch.
EDA and Preprocessing
The main problem is the cleaning of the quotes. Since the online quotes are written by users and not filtered, there are many duplicates. Especially small quotes were often found in a large share, and sometimes with few changes in the writing (articles, preposition, and punctuation). To find them I looked if a single string was present in any quotes. Then I did the same operation but using a clean pre-processed text (with textacy). And for last same operation using the Countectorizer with a fairly big gram (5-6 words). I probably could have used only the last one, but at the beginning, I didn’t realize any little differences between the quotes (that I mentioned before). Since these steps were not enough to remove the duplicates I had to do the last drop manually, using the gram system and the method str.contains (word in gram). I also got the fourth iteration to look for quotes about the authors and not from the authors. Some of these quotes could have been still interesting, but since I could not check them manually. I could read most of the quotes, but I read some. Whenever I was founding a too noisy, useless quote I removed manually. For the same reason, I have investigated. (For example Katie Hopkins)
Since the median of the quotes is larger than 30 words in every category I chose to eliminate every quote with less than 8 words. As last step of the cleaning, I applied lemmatization.
Baseline and Vocabulary
To create balanced classes I took the same number of random data for each class, the number of quotes has been chosen from the number of the weakest category (Progressive). The baseline is 0.2
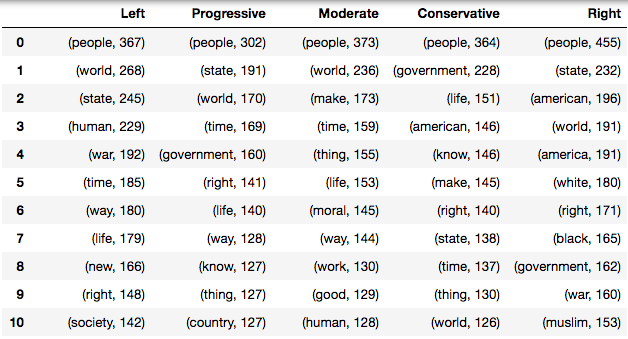
Investigating the vocabulary for each class we realized immediately that the goal will be very hard as most of the frequent words are the same, in each category. The first most used word by category is the same for each class: “people” for the quote, the second is “world” in three categories and in the top 5 in the left two. We can see that the two extreme categories have more unique words and concepts, and we notice also that many categories contain words opposite to their ideology. This happens because they talk about other categories.
The extreme ideologies have more words, and median and mean of length of quotes bigger. Moderate take the last position in all these ranking.

Modelling
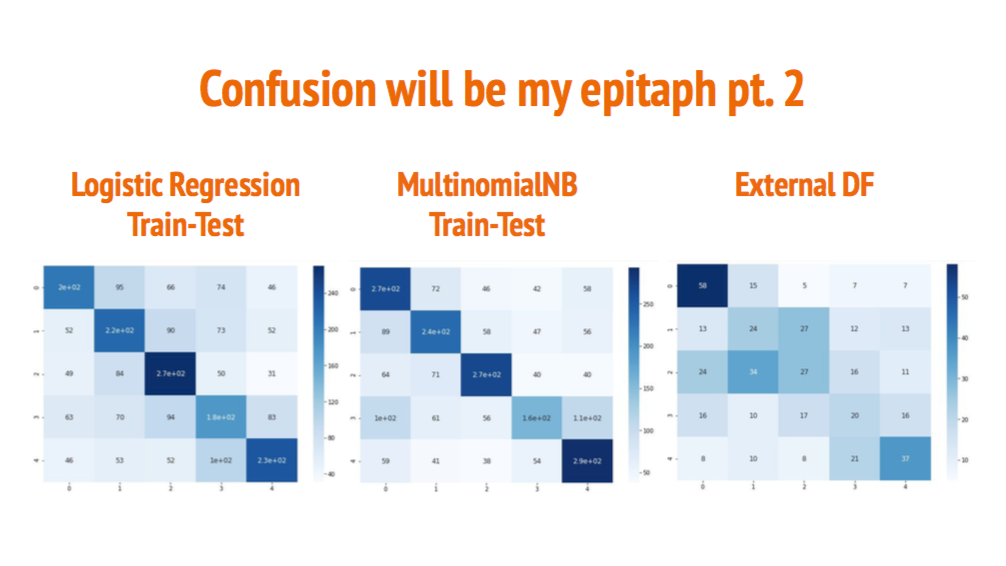
I started creating a pipeline using CountVectorizer. After inspecting the vocabulary, I increased the stopwords with other few not very useful words that came out in the top 30 (auxiliary verbs especially). Logistic Regression is the first model to try in the pipeline: A score around45%-46% on the test set show us that a pattern could be found in the words. From the confusion matrix, we can clearly see the diagonal of the true value, and often the neighbor category has the highest values in the false negative. Since the final dataset is created random, I chose to not save it and run a different dataset every time. After several observations, I can say that the difference is very little every time. Conservative is the class with the lowest value of precision and recall. In some particular situation of the random dataset, the left became the first false negative for the conservative. From the most important coefficient, we notice that in the left we have few words that describe the conservative (capital and neoliberal) and conservative have communist. At the same time, there is some similarity in the negative coefficients. Overall the coefficients start to track a line and give us some boundaries for the categories.
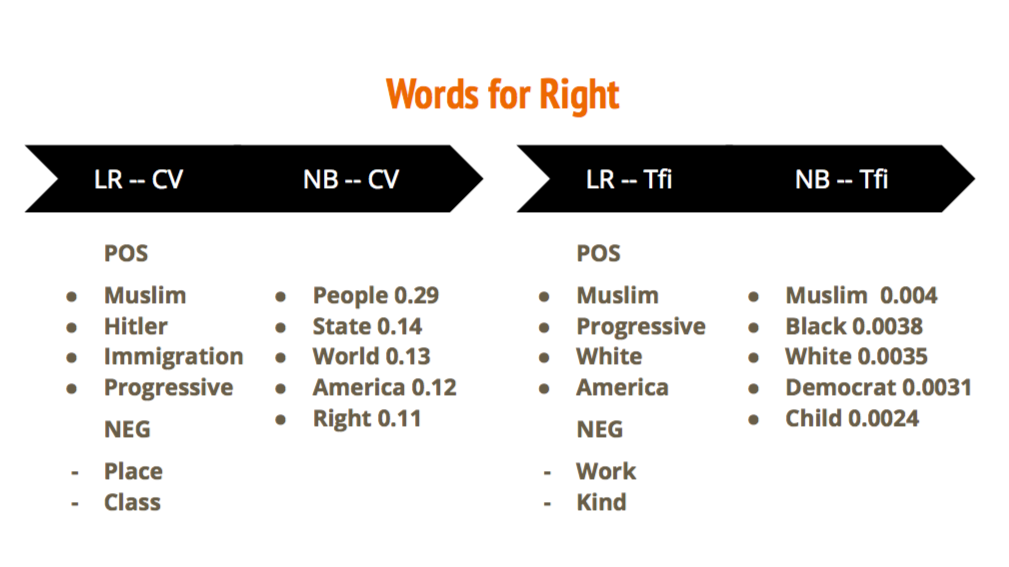
After trying other classifiers, the best score happens to be with MultinomialNB. But if the score is slightly better, confusion matrix, precision, and recall became more imbalanced. The previous problem between left and conservative became bigger. One of the reasons for this mismatch is that the machine predicts left more than other categories. In fact, left has a pretty low precision (only conservative have the worst precision) and the higher recall. Words like left, Marx, happy, history…push the choice to the left; America, republican to conservative; Israel to the right; books to the progressive and topic about morality in the center. So if Noam Chomsky uses the word Israel will be label as Right category.
The result of the little external dataset is lower. This show that our model overfit a little on the authors, but confirm mostly what we saw in the other database. Generally, the model doesn’t behave too bad at the extreme but is more confused in the center.
We can explain this behavior also from real life. The extreme is the categories that want to change the status quo, while the categories in the middle, in different ways, want to keep it. And we could notice this almost from the beginning and the most frequent words.
Using the TfiVectorizer we see a little improvement in the score, both with Logistic Regression and MultinomialNB. The coefficients also didn’t change that much. Overall the behavior of the machine is very similar. On the test set, we have a good improvement to identify the class moderate and still decent on the extreme. Looking again at the coefficients we can notice that Progressive are different from the Left because are more related to government and economic words. The worst category to identify is the again the conservative which finish in the right (an error that can be acceptable in same cases) and left. most likely for the same reason we met with the Countvectorizer. We also notice that some “family” related words appear in the right side of the spectrum. So every quote that contain the words child, father, are probably categorised as conservative or right. The right keeps words typical of nationalism and of the far right : muslim, islamic, Israel, jews. Exactly like the machine didn’t change much in the big dataset, also in the external dataset almost everything we notice in the previous analysis is confirmed.
Using a threshold confusion matrix I built we confirm even more that the strongest probability are in the extreme categories. The reason is again in the different words used from these categories. This shows also, that the confusion that the machine has for the 3 categories in the centre, comes from low probabilities.
The Precision Recall Curve and the ROC, shows Left and Right above any other, and centre in middle. Not great for Progressive and Conservative. These last two categories are sometimes even lower than the baseline in the external dataset, probably due to the overfitting of the authors.





Voting
After a careful manual evaluation of the misalignments, I noticed that each model behaves in a partially different way. All retain a discreet consistency. Because of this behavior, we choose to use a forecast type of media using a voting classifier. although the score only increases in the external dataset, there are slight corrections and some decisions become more tolerable.
Mentioning other methods that have worsened the result
As of last things, I tried Sentiment Analysis and Word2Vec. Sentiment Analysis with Vader brought a massive bias on the Progressive class. In the external dataset, almost every prediction is Progressive. A tool that in this case didn’t help and I am not sure can improve in a case of ideological detection. Word2Vec had a lower score than the main models analysed, and also every class performs slightly worse than the other models. In the external dataset predict with great precision and recall the Left and Right, but the rest is very confusing. It needs further analysis, but it is still a new method for me, so it will be part of future implementation.
Conclusions
- The data is very noisy. Manual labeling would definitely tune the machine. To keep the objectivity, maybe some expert or student of science politics/politics would create an interesting dataset.
- To accomplish this would be better to have better research not only with the quotes available on the web but from books and academic paper, newspaper and blog.
- The labeling by authors can be good but it has a big limitation: It is always possible that the mind of the person, usually more coherent than most of the politician’s mind, can float. I feel that every time we try to have a rigid classification about something not so rigid, like the human mind, is forced and no natural. A biased author not always will have biased content.
- The machine evaluates at the same way a close (acceptable) error with a far category. A method for ordinal classification could fit better our problem.
- To define such a complex topic it requires more data. The machine works mainly combining words. More combination we use to feed the machine, more likely the opinion mining can be better.
- Since I use the last 60 years, the machine not overfit to the last period time, actually probably underfit. At the same time, new and specific topics (like Brexit) are meaningless.
- There is a big homologation in the political lexicon. Especially in the 3 central ideologies.
- There are words like “right” which are very difficult to interpret, due to many meaning that the word could have. Metaphor and humor are a big problem too.
- There is a patter that needs to be investigated to get better result.
Future implementations
- Better Dataset, different Dataset: Quotes without noise, investigate the same method with a Twitter database, and newspaper/blog database.
- Use topics as part of the features
- Locate the Database in the space and in time: Use English was important to collect more data but to improve, create a model for each country (space) and for each topic could bring a massive evolution in the project. Exactly we should locate the database in a shorter period of time.
- Create a specific metric evaluation that could be compatible with this ordinal classification problem. Bespoke confusion matrix and classification report.